Mäetagused vol. 68
Summary
-
Some features of Estonian Swedish prosody
Eva Liina Asu
Senior Research Fellow in Phonetics, Institute of Estonian and General Linguistics, University of Tartu
eva.liina.asu-garcia@ut.ee
Keywords: prosody, word tones, rhythm, Swedish, varieties of Estonian Swedish
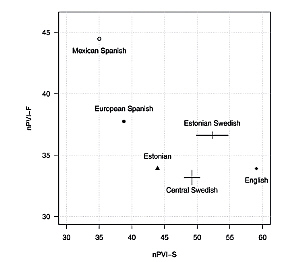
Estonian Swedish was traditionally spoken on the western coast and islands of Estonia. Nowadays, it is almost extinct, surviving only as a language of occasional communication of some elderly speakers who emigrated from Estonia to Sweden as children during World War II. Estonian Swedish is a typologically interesting variety of Swedish, as it retains a number of archaic segmental features (e.g. Old Scandinavian diphthongs) and has been influenced by its most important contact language, Estonian. The article addresses such aspects of Estonian Swedish prosody as word accents and rhythm. An investigation of the realisation of tonal accents in disyllabic words showed that Estonian Swedish (like Finland Swedish) lacks the lexical pitch accent distinction that is characteristic of Standard Swedish. A comparative study of rhythm in read speech explored the hypothesis that Estonian Swedish may be intermediate between Swedish (as represented by Central Swedish from the Stockholm area) and Estonian. The results showed, however, that the durational values of Estonian Swedish rhythm are very similar to those of Central Swedish.
-
-
Variation in the pronunciation of Estonian short plosives and its affecting factors
Liis Ermus
Archive administrator and junior researcher, Institute of the Estonian Language
liis.ermus@eki.ee
Keywords: acoustic phonetics, coarticulation, Estonian language, plosives, reduction, spontaneous speech, voicedness
Plosives in Estonian have been considered voiceless. However, analysis has shown that short plosives tend to get at least partially voiced and otherwise reduced in connected speech. This seems to be quite a universal tendency in different languages.
The present paper investigates short plosives in intervocalic position in most frequent content words.
Phonetic materials were extracted from the Phonetic Corpus of Estonian Spontaneous Speech. Patterns in the reduction of plosives and possible influences of stress and vowel context were investigated.
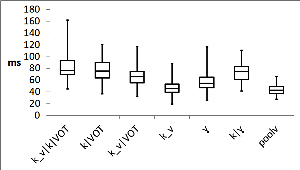
Two kinds of allophones emerged – those that were fully realised and had a distinguishable release burst, and the reduced ones that had lost the burst phase. The amount of reduced tokens differentiated the velar plosive [k] from others. As [p] and [t] both had over 65% of fully realised tokens, but over 60% of [k] tokens were reduced. [k] also had most different allophones. Among fully realised tokens there were voiceless, partially voiced, and fully voiced allophones. The voiceless allophone was the rarest, 19% tokens of [p] and only 10% of [t] and [k] were voiceless. Most frequent allophones among phonemes were partially voiced for [p] (29%), fully voiced for [t] (37%), and reduced voiced for [k] (47%).
Closure durations were related to place of articulation. [p] had the longest average durations and [t] the shortest. Across all tokens [k] and [t] had similar average durations but within allophones durations were closer between [k] and [p]. Burst durations were the longest, around 30 ms for [k] and almost the same duration, between 21–23 ms, for [p] and [t], with the exception of the voiceless allophone [t], which was 27 ms. Closure durations differed significantly between [p] and [t] and burst durations were significantly different between [k] and other phonemes.
Stressed positions included both lexical and contrastive stresses. Stress had some effect on the allophonic distribution but almost none on durations. As expected, there were more voiceless and partially voiced tokens in stressed position and more reduced tokens and total loss in unstressed position. Differences were the biggest for [t] and the smallest for [k]. Durations differed very little, whereas none were statistically significant.
Vowel context had some influence on allophonic distribution. The influence was the biggest on [t]. Overall, there were more fricative and approximant tokens around [i].[t] had more partially voiced tokens and less voiced tokens around labial vowels [o, u]. There were more reduced [k] tokens around [a] and [i]. On durations the vowel context again influenced [t] the most. Durations between all vowel contexts were statistically different for [t] (p >.01); the longest durations appeared after [i].
In general, the present study confirms the results of the previous ones. Allophonic distribution is very similar to the previous study of Estonian spontaneous speech. Closures were at least partially voiced in most cases which refer to carry-over voicing of the previous vowel. Vocal cord vibration stops for a very brief time or does not stop at all during short closure times. Burst durations appear to be longer in spontaneous speech than in read speech. Little influence of stress is in accordance with findings in the studies on Estonian and some other languages. Vowel influences were dependent on the place of articulation. Bilabial [p] was the least affected both in allophonic variation and in durations. Velar [k] was influenced by the vowel context but it mostly occurred in whole as extensive reduction; different vowels had more effect on the allophonic variation than in the case of [p] but durations were almost unaffected. Influences on [t] mostly occurred as significant duration differences; yet, also some differences in allophonic variation occurred.
-

-
From prosody to melody: Methodology of Estonian scripture prose text based monodic a cappella chant or Estonian sacred plainchant
Eerik Jõks
Lecturer and Research Fellow Estonian Academy of Music and Theatre
eerik@ekn.ee
Keywords: Bible, church music, Gregorian chant, Holy Scriptures, liturgical chant, medieval sacred Latin monody, plainchant, prosody, psalm, vernacular
Latin monody, plainchant, prosody, psalm, vernacular
The most widespread Estonian Christian chant is Lutheran chorale, which is based on a text of strophic verses, in which all verses can be sung with the same tune. The roots of the written tradition of the Western Christian chant (9th–10th cc.), however, are in the prose text of the Latin Bible. Nowadays a chanted vernacular prose text from the Bible or vernacular plainchant has found its way to the Lutheran repertoire. The article demonstrates how consideration of the parameters of Estonian prosody can contribute to the creation and practice of Estonian plainchant. In other words, the article describes a system of principles following which the stylistically versatile Estonian plainchant is created. The styles of vernacular plainchant are: (1) contemplative, (2) declarative, and (3) free style.
The Estonian or vernacular plainchant can be defined either through the categories of linguistics or those of Christian piety. In terms of linguistics, the vernacular plainchant follows the three parameters of prosody: (1) the temporal parameter, (2) the dynamic parameter, and (3) the intonation parameter, while pronouncing the texts of the Holy Scriptures and realising as well as considering these three parameters in shaping the melodic information and bearing it in mind in performance. In terms of Christian piety, the vernacular plainchant is a monodic musical a cappella pronunciation of the unaltered prose texts of the Holy Scriptures, which is based on prayerful concentration and/or sacred conviction, and is trying to follow in every point the authority of the Word of God and consider the prosodic peculiarities of a particular language.
The contemplative style is based on “switching off” the personal prosodic intonations of the text. To a certain extent the result resembles a phenomenon that is known in music performance as “recitation”. However, it differs from recitation, because there is no intention of a performer to express him- or herself through music. The result that is similar to recitation happens simply because the performer begins to say the syllables at the same height without any intention to sing. Melodic formulas are then applied to this recitation-like contemplative talking.
There are two kinds of melodic formulas in Western plainchant: (1) formulas with accentual cadences, and (2) formulas with cursive cadences. Accentual cadence takes into consideration the prosodic principles of Latin as well as other Indo-European languages in which an accented syllable is usually perceived as the longest syllable of a word. This means that the accented syllables are always marked with dominant notes of a cadence. Cursive cadence, on the other hand, always applies the same amount of syllables in the cadences without any accentual considerations. Estonian prosody differs significantly from Indo-European prosody, as the accented syllable is not always the longest syllable of the word. Therefore, in Estonian formula-based plainchant a cursive principle should be preferred.
While the contemplative style stands on “switching off” personal prosodic interpretation, the declarative style attempts to achieve the opposite: personal conviction in pronouncing the text should be enhanced and extracted as a melody. The free style is a further development of the declarative style, in which the composer decorates the melody according to his or her personal creativity and taste.
Describing the contemplative, declarative, and free styles of Estonian plainchant showed that we are dealing with a genre of extensive possibilities, which appreciates our mother tongue, recognises the tradition from which our musical culture springs, and gives a dignified position to the core text of the Estonian language and culture – the Bible.
-
-
Words with variable quantity degrees: Auditory assessment and pronunciation preferences
Mari-Liis Kalvik
Senior lexicographer and researcher of experimental phonetics Institute of the Estonian Language
Mari-Liis.Kalvik@eki.ee
Liisi Piits
Speech technology researcher Institute of the Estonian Language
Liisi.Piits@eki.ee
Keywords: auditory assessment, Estonian, phonological variation, reading experiment, variation of quantity degrees
For the studies of quantity degrees, words were chosen which the Dictionary of Standard Estonian (ÕS 2013) lists as being pronounced with both the second and third quantity degree. As Estonian text-to-speech synthesis relies in its determination of pronunciation on this dictionary and automatic text analysis cannot handle multiple outputs, the aim is to find out which variant is more common among language users, to give the preference to one of the pronunciation variants.
This study is based on a reading experiment conducted with 50 informants (36 women and 14 men), in which each informant read 52 sentences aloud. These sentences contained 49 target words, i.e., words of variable quantity degrees; in total, the study yielded 2438 pronunciation instances to examine. Each pronunciation instance got an audio assessment made by 2 listeners. If their quantity degree assessment were conflicted (one listener gave second and another gave third quantity assessment) the third listener was then ultimate decider.
There are two main questions we would like to answer. First of all, we are interested in finding out how much an auditory assessment depends on listeners and how much the estimations are changed during the evaluation. Finding answers to these questions will help us to reach the main goal of our study: to find out the main tendencies in how the words with variable quantity degrees are pronounced.
Comparing the auditory assessment of the first and second listener, it turned out that of the 2438 pronunciations, the assessments of two listeners differed in 375 cases (15% of all the pronunciation instances). In case of inconsistencies, we gave the first listener the opportunity to make a new assessment. It turned out that the first estimation was changed on average in 50% of the instances.
These 375 cases in which the first and second listener’s quantity degree assessments were conflicted were in the end changed by 72% of cases. This means that for all the 2438 pronunciations, the listeners changed their first assessment by an average of 12% of the cases.
On the basis of the informants’ pronunciation, the words were grouped into three categories: the second quantity degree (words in which pronunciation with the second quantity degree dominated), variable quantity degree (where neither the second nor the third quantity degree accounted for more than 2/3 of all pronunciations), and the third quantity degree (words in which pronunciation with the third quantity degree dominated).
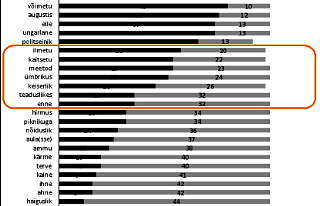
Based on the auditory assessment, 20 words fell into the second quantity degree group, in which words were pronounced predominantly with the second quantity degree. These words were mullu ‘yester-year’, alles ‘only’, teisal ‘elsewhere’, ilma ‘without’, toimekas ‘expeditious’, soodus ‘favourable’, tallinlane ‘citizen of Tallinn’, andekas ‘talented’, rõõmus ‘jolly’, kirju ‘varicolored’, hilja ‘late’, võimekas ‘capable’, maitsekas ‘tasteful’, kiire ‘fast’, täiuslik ‘perfect’, võimetu ‘incapable’, augustis ‘in August’, eile ‘yesterday’, ungarlane ‘Hungarian’, politseinik ‘policeman’. Listing starts with a word which has the largest amount of second quantity degree pronunciation instances (100% of readers pronounced mullu as a word with the second quantity degree) and ends with the smallest amount of second quantity degree pronunciation instances (72% of readers pronounced politseinik as a word with the second quantity degree).
The third quantity degree group contained 22 words. These words are saatanlik ‘satanic’, saatuslik ‘fateful’, peenelt ‘finely’, kuulus ‘famous’, rahvuslik ‘national’, äärmuslik ‘extreme’, looduslik ‘natural’, jaanuar ‘January’, kangelane ‘hero’, pealik ‘chief’, nooruslik ‘youthful’, haiguslik ‘diseaseful’, ahne ‘greedy’, ihne ‘penny-pinching’, kaine ‘sober’, terve ‘healthy’, kärme ‘fast’, ammu ‘erst‘, aula ‘hall’, nõiduslik ‘bewitching’, piknikuga ‘with picnic’, hirmus ‘horrible’.
The variable quantity degree group contained 7 words: ilmetu ‘inexpressive’, kaitsetu ‘defenceless’, meetod ‘method’, ümbrikus ‘in envelope’, keiserlik ‘imperial’, teaduslik ‘scientific’, enne ‘before’.
-

-
On techniques of musical development and construction of musical dimension in the sound poetry of Jaan Malin
Kerri Kotta
Professor of music theory Estonian Academy of Music and Theatre
kerri.kotta@gmail.com
Keywords: language, musical form, sound poetry, techniques of musical development
Sound poetry is an artistic form in which phonetic qualities are usually given preference over the semantic content. In sound poetry, it is especially the rhythm and sound (timbre) of words which is used to build up meaningful structures. Due to this feature, sound poetry resembles the so-called absolute music, i.e., classical instrumental music based on extended and complex forms. In the absolute music, the unfolding of a work’s musical form is simultaneously understood as its content (hence the idea of formal aesthetics that the way of saying is, in a sense, equivalent to what is being said). This is why the analysis of form plays such an important role in the classical music. This article suggests the idea that the tools used in the analysis of formal structures of classical instrumental music can be applied also to sound poetry to uncover its content and meaning.
The article concentrates on the sound poetry of Estonian poet and writer Jaan Malin. Malin’s interest in sound poetry was awakened by another Estonian poet Ilmar Laaban, whose works Malin saw as examples. In his works, Malin uses several techniques to achieve timbral continuity of the text, including repetition, fragmentation, and liquidation, timbral “links”, timbral palindromes or retrogrades, transformation of the sound of words, and formal overlaps and interpolations. Occasionally Malin applies metrical structures characterising also the main theme, i.e., the entire musical phrase or group of phrases of a musical work.
In Malin’s works, the repetition usually displays a word or a group of words followed by a number of its timbral equivalents, i.e., the words or sound forms (new words invented by the poet having no concrete meaning) that include the same number of syllables, but which are slightly different from the original form. Sometimes longer words or word groups are gradually replaced by shorter words, which creates intensification. Such a phenomenon is referred to as fragmentation in this study. In specific contexts, the fragmentation can be followed by an opposite phenomenon – the summation (shorter words are followed by longer words), which in the analysis of a musical sentence is usually referred to as liquidation.
To connect larger formal units, Malin sometimes uses “links”, i.e., the words or word-like fragments having similar sound. The “links” can be direct or indirect. In creating a new “link”, a word is followed by another word that displays the same vowels in the same or reverse order. The first corresponds to the direct, and the second to the indirect “link” accordingly. The latter is also referred to as timbral palindrome or retrograde in this study. Sometimes, there is also a gradual transition from one formal section to another. Such transitions are described as transformations since the dominating words of a new formal section appear as a result of a continuous elaboration of words governing the preceding section.
The shortest and simplest way to link two sections is to use a word that functions simultaneously as the last word of the preceding and the first word of a new section. Analogous to music, such a link is referred to as overlap. In addition, Malin in his works occasionally takes the position of a commentator, expressing his opinion on the text. This creates a kind of narrative caesura, interruption of continuity, which can be paralleled with that of interpolation in music analysis.
Malin does not use the techniques of musical development for their own sake. Rather, he uses these to enter the dimension of music as he uses the semantic content of words to return to the dimension of language. From the perspective of language, switching between the two dimensions can also be understood as semantic “release” or “recharge” accordingly.
-
-
Temporal variation in singing as interplay between speech and music in Estonian songs
Pärtel Lippus
Senior Research Fellow Institute of Estonian and General Linguistics University of Tartu
partel.lippus@ut.ee
Jaan Ross
Professor Department of Musicology Estonian Academy of Music and Theatre
jaan.ross@gmail.com
Keywords: Estonian, linguistic duration, musical rhythm, quantity language, syllable, tone language
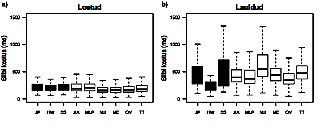
Acoustic syllable durations were measured in Estonian utterances performed in parallel as recited and sung. A systematic effect of phonological syllable length was found irrespective of the group of participants (contemporary or historic). This effect of syllable length was modified by the mode of performance: in music, it was present considerably less than in speech. In music, the effect of syllable length in turn was modified by song: it was present in two of the three songs, but absent in one song. The above results suggest that the correspondence between linguistic duration and musical rhythm in a quantity language such as Estonian is loosely defined. The nature of the correspondence between linguistic quantity and musical rhythm may be considered, to a certain extent, analogous to the tone-tune relationship in tonal languages.
-
-
Evaluation of automatic speech segmentation
Einar Meister
Senior researcher, Tallinn University of Technology
einar.meister@ttu.ee
Lya Meister
Researcher, Tallinn University of Technology
lya.meister@ttu.ee
Keywords: automatic segmentation, Estonian, phone boundaries, segment durations, speech corpora, word boundaries
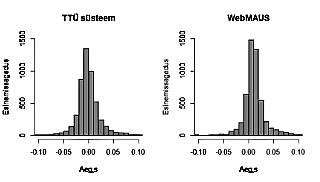
The use of large speech corpora in phonetic research depends to a great extent on the availability and quality of phonetic segmentation and transcriptions. As a rule, the best quality of segmentation is achieved by human transcribers who perform time-consuming and tedious manual work. However, tools for automatic segmentation exploiting typically HMM-based forced alignment methods have been developed for different languages. In recent years, two automatic systems as free online services have become available for Estonian: (1) the system developed at Tallinn University of Technology (https://phon.ioc.ee/dokuwiki/doku.php?id=projects:tuvastus:est-align.et), and (2) the multi-lingual tool WebMAUS (https://clarin.phonetik.uni-muenchen.de/BASWebServices/).
In this study we evaluate the performance of the two systems against human transcribers. The test set includes Estonian read speech produced by: (1) four L1 adult subjects, (2) six L1 adolescents, and (3) four L2 adult subjects. The reference segmentation data including 27 sentences from L1 subjects and 10 sentences from the other subjects were produced manually as Praat textgrid files with two tiers (word-level orthographic and phoneme-level SAMPA transcription); the automatic systems have produced similar textgrid files. In total, 1179 word boundaries and 5050 phone boundaries were compared.
The results show that both systems performed more accurately for L1 adult speech and were less accurate in the case of adolescent and L2 speech. While the TUT system outperformed WebMAUS in L1 adult speech, then in L1 adolescents and L2 speech WebMAUS produced more accurate results. Despite the deviations in phone boundaries, the durations of vowel and consonant segments measured from automatic and manual segmentations of L1 adult speech differ only marginally. This suggest that the accuracy of both automatic systems seems to be sufficient for speech technology needs and could also be used in acoustic studies of L1 adult speech. However, both systems need improvements in order to reach the accuracy of automatic segmentation tools available for English.
-
-
Acoustic correlates of sentence stress in Estonian
Meelis Mihkla
Senior Research Fellow / Head of Department Institute of the Estonian Language
meelis.mihkla@eki.ee
Heete Sahkai
Research Fellow Institute of the Estonian Language
heete.sahkai@eki.ee
Keywords: duration, Estonian, intensity, pitch, sentence stress, spectral emphasis, vowel quality, quantity degree
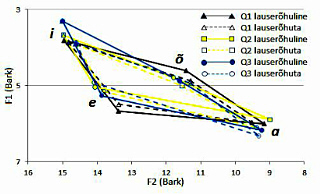
The study examines the acoustic correlates of sentence stress in Estonian. The data consists of 18 four-word sentences read aloud by nine speakers in answer to three questions eliciting different information structures. The test words include six sets of triplets of words differing minimally in quantity degree. The words occur in three different stress conditions: (i) after narrow focus (the unstressed condition); (ii) as the nuclear accented word in a broad focus sentence (the stressed condition); and (iii) as an emphatically accented narrow focus (used for the purposes of normalisation). The test word is always the third word in the four-word sentence in order to avoid interferences from boundary signals.
The potential correlates under study are the following: (i) the F0 range and peak height of the test word, measured in the test words with a H*L pitch accent respectively as the difference between the F0 maximum of the stressed syllable and the F0 minimum of the unstressed syllable, and as the difference from the mean F0 maximum of the test word in the three stress conditions produced by a speaker; (ii) the duration of the test word in the different stress conditions, measured as the difference from the mean duration of the test word in all three conditions; (iii) the intensity range and the maximal intensity level of the test word; (iv) the values of the F1 and F2 formants as indicators of vowel quality; and (v) the spectral emphasis of the stressed syllable of the test words. The above values were analysed separately for the three quantity degrees in order to determine a potential effect of the prosodic structure of the word on the acoustic realisation of sentence stress. The data was statistically analysed with the Systat software package. The classification power of the different parameters was determined, using linear discriminant analysis.
The strongest correlate of sentence stress turned out to be F0, as was expected, given that sentence stress is phonologically realised as a pitch accent. From the two F0 values, the peak height was the stronger one, with a classification power of 89%, F0 range permitting to classify correctly 76% of the data. Almost equally strong correlates as the F0 range were the duration and intensity level, classifying correctly respectively 75% and 73% of the data. Vowel quality and spectral emphasis did not correlate significantly with sentence stress. The results also revealed an effect of lexical prosody on the acoustic realisation of sentence stress: the lengthening and the rise of the intensity level were the largest in the stressed words of the third (overlong) quantity degree.
-
-
Quantity degrees in the metre of Seto runosong

Janika Oras
Senior Research Fellow, Estonian Folklore Archives, Estonian Literary Museum
janika@folklore.ee
Sulev Iva
Lecturer in South Estonian Language and Culture Institute of Estonian Language and Comparative Linguistics, University of Tartu.
Research Fellow, Võro Institute
sulev.iva@ut.ee
Keywords: Baltic-Finnic runosong, South Estonian phonology, quantity degrees in Estonian and Seto languages, runosong metre, Seto runosong
The difference of Seto runosong from the runosong of other areas is related to specific melodies. At the same time, Seto verse is shaped by the changes in the South Estonian language. This article focuses on the songs, the melodies of which belong to an older layer of the singing tradition: these are in the one-three-semitone scale and each verse syllable corresponds to a note of the same length in the melody. As the main case, the singing performances of a melody of lyrical and epic songs, known also as the ‘feast melody’ (praasnikaviis), are analysed. The reference material is metrically more complicated refrain songs – harvest songs with lelo-lelo-lelo refrain (lelotamine), wedding songs with kaśke-kańke refrain (kaaskõlõmine), and game songs with heiko-leiko refrain (leigotamine, ‘The Horse Game’). The main question is how the performers apply metrical entities to linguistic entities – which are the principles of placement of the words of different quantity degrees into the verse positions.
The Seto and neighbouring Võro songs resemble each other by the distinctive metrical quality of the syllables of overlong quantity degree (Q3): all Q3 initial syllables or monosyllabic words can be placed into two verse positions. In the 8-position verses of the analysed Seto songs, the initial syllables of Q3 trisyllabic words are regularly placed into two positions. The division of the initial Q3 syllable is used to form not only the regular trochaic lines, but also broken lines (lines with the word stress placement of broken lines). Seto songs feature quite evident metrical opposition between Q3 syllables and Q1-Q2 syllables. The latter are used similarly to each other – the first two syllables of Q1 and Q2 words can be assembled into one verse position and both can be placed into the “weak” positions of the line.
Related to the increasing importance of the word stress in the language, Estonian runosong has moved from a quantitative verse system towards the syllabic-accentual system and the number of broken verses is small, especially in some areas like Võrumaa (Sarv 2015). Still, in the analysed Seto songs about 15% of the lines follow the word stress placement of the broken lines (2+3+3 structure). These lines do not correspond to the quantity principles of the runosong – rather, the broken line has remained a model for positioning lexical stresses. In addition, the refrain songs contain 7-position lines – supposedly inspired by broken line structures. In some ways the songs with a changed quantity system seem to conceal traces of the common quantity system of the Finnic runosong: in the weak positions of the main verse with 2+3+3 structure, the Q1 syllables dominate (and are accompanied by a smaller number of Q2 syllables).
-
-
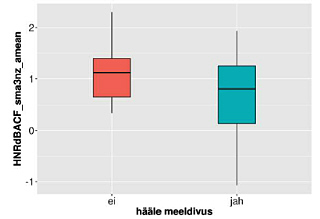
Computational paralinguistics challenges and Estonian voice likability
Hille Pajupuu
Leading researcher, Institute of the Estonian Language
eki@eki.ee
Jaan Pajupuu
Software developer
eki@eki.ee
Rene Altrov
researcher, Institute of the Estonian Language
eki@eki.ee
Keywords: computational paralinguistics, eGeMAPS, speech acoustics, speech corpora, voice likability
This article looks into tendencies of the last decade in computational paralinguistics: ascertaining of speaker traits and states in voice, and the requirements set for the related speech corpora. It introduces the Estonian voice corpus and the ability to acoustically characterize voice likability and identify it automatically, using the expanded Geneva Minimalistic Acoustic Parameter Set (eGeMAPS) for voice research and affective computing.
-
-
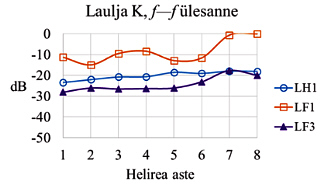
The stability of voice source spectral envelope in singing scales with varying dynamics
Allan Vurma
Senior Researcher, Estonian Academy of Music and Theatre
vurma@ema.edu.ee
Keywords: classical singing, evenness of the voice, glottography, inverse filtering, singer’s formant, spectral analysis, voice dynamics
The aim of the present work was to investigate whether and how the timbre-related voice parameters change when classically trained vocalists sing vocal tasks with varying voice dynamics and pitch. This research question was motivated by a standpoint often expressed in literature that one of the goals of classical voice training is the evenness of the sound. In the empirical experiment we asked ten male vocalists (opera and oratorio soloists, and voice students) to sing one-octave ascending D-major scales (from D3 to D4) in three different ways: (1) with most habitual dynamics without intentional dynamic changes; (2) with sempre crescendo; and (3) with sempre diminuendo. We recorded the performances in a studio with low reverberation. Then we calculated the average power spectrums for each sung note with the help of software Sopran 1.0.10. We determined the levels of the fundamental component and the singer’s formant in relation to the level of the strongest peak of the spectrum. We also measured the levels of the sound pressure and the values of the closed quotients and quasi-contact quotients (which characterize the strength of the glottal adduction during phonation). The values of investigated parameters changed systematically during the vocal tasks in the case of all singers. Some of these changes had purely acoustical reasons, which cannot be controlled by the vocal technique of the singer. However, some singers used the strategies, the aim of which was probably the improvement of the perceived evenness of the voice. One of such strategies was the creation of difference between the piano and forte dynamics mainly by changing the timbre and not so much by altering the sound pressure level of the voice. The opposite strategy was the changing of the sound level while keeping the variability of the relative level of the singer’s formant small (which characterizes the brightness and carrying power of the voice). The perceived evenness of the voice may also depend on some other voice properties that we did not address in this work. The pattern of changes in the voice parameters may also depend on the used vowels and pitch range.
News, overviews
-
In memoriam
Christie Davies
December 25, 1941 – August 26, 2017.Piret Voolaid’s obituary in English can be read in Folklore: Electronic Journal of Folklore 70.
-
-
Testing the ways of dwelling: 13th congress of the SIEF in Gottingen
Mare Kõiva’s recollections of the 13th congress of the International Society for Ethnology and Folklore in Gottingen on March 26–30, 2017.
-
-
The 29th international conference for humor studies in Montreal
Piret Voolaid and Liisi Laineste write about the 29th annual conference of the International Society for Humor Studies, which took place at the University of Quebec, Canada, on July 10–14, 2017.
-
-
The 3rd joint conference of Balkan and Baltic scholars in Vilnius, Lithuania
Mare Kõiva gives an overview of the conference “Balkan and Baltic States in United Europe: History, Religion, And Culture III”, which took place at the Lithuanian Institute of History in Vilnius, Lithuania, on October 9–11, 2017.
-
-
Mari religion under observation
Eva Toulouze introduces the doctoral thesis by Mari ethnologist Tatiana Alybina, “Changes in Mari religious traditions in the post-Soviet period”, defended at the University of Tartu on November 10, 2017.
-
-
Folkloristic fieldwork: Chapter and verse
Folkloristlikud välitööd. Compiled by Merili Metsvahi. Tartu: University of Tartu Press, 2017. 358 pp.
Book review by Reet Hiiemäe.